![[코드잇] 머신 러닝 기본기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FoFtoz%2FbtsJguJku2L%2F3ckvXSYkH6G7cBbXHnfUk0%2Fimg.png)
01. 머신 러닝이란?
Machine Learning (기계 학습)
: 기계가 학습을 통해 발전
프로그램 vs 머신 러닝 프로그램
: 일반 프로그램과 달리 머신 러닝 프로그램은 경험을 통해서 스스로 업무 능력 향상
ex) 스팸 메일 분류 프로그램
일반 프로그램
- 인간이 직접 스팸 메일의 특징들을 파악해서 컴퓨터에게 분류하는 방식을 알려줌
- 완벽하게 스팸 분류가 불가능
- 인간이 복잡한 규칙들을 모두 찾아낼 수는 없기 때문에 이 프로그램을 크게 개선하기 어려움
머신 러닝 프로그램
- 인간인 우리가 규칙을 찾아서 알려주는 게 아니라 프로그램이 스스로 규칙을 찾도록 하는 것
- 머신 러닝을 할 때는 이런 규칙들을 코드에 명시하는 게 아니라 컴퓨터가 직접 이 규칙들을 찾아낼 수 있도록 하는 것
- 머신러닝은 데이터를 통해서 가능하다
- 새로운 데이터가 있으면 이 새로 주어진 데이터를 통해 더 정확한 규칙을 찾기 위해서 살짝 조율함
- 새로운 데이터로 계속 학습시키면 100% 확률로 스팸을 맞출 수 있게 됨

톰 미첼 (카네기 멜런 대학교수)
기계학습 : 기계가 학습한다는 건, 프로그램이 특정 작업(T)을 하는 데 있어서 경험(E)을 통해 작업의 성능(P)을 향상시키는 것

02. 수강 가이드
선이수 지식 안내
이번 토픽에서는 파이썬이라는 프로그래밍 언어를 사용합니다. 파이썬을 써 본 적 없다면 파이썬 기초부터 공부해 보세요! 그리고 NumPy와 pandas를 사용해서 데이터를 다루는 방법을 익힌 뒤에 이번 토픽을 수강하는 것을 추천합니다.
아직 잘 모르는 내용이 있어도 걱정할 필요 없습니다. 코드잇의 [데이터 사이언티스트 커리어 패스]나 [머신 러닝 스킬 패스]를 참고해서 필요한 부분만 학습해 보세요!
개발 환경
이번 토픽에서는 다음과 같은 프로그램을 사용합니다. 여러분의 PC에서 직접 실습해 보고 싶다면 설치 가이드를 참고해서 프로그램을 설치해 주세요!
Anaconda (Windows 설치 가이드, macOS 설치 가이드)
Anaconda를 설치하면 Jupyter Notebook, numpy, pandas, matplotlib 등 데이터 사이언스를 할 때 주로 사용되는 툴들이 함께 설치됩니다.
라이브러리 버전 안내
우리가 사용하는 소프트웨어나 라이브러리의 버전은 끊임없이 변화하고 있다는 사실, 알고 계시나요? 버전 차이에 따라 함수 이름, 파라미터, 실행 결과 등이 조금씩 바뀌기도 하죠. 코드 작성 시점에 따라, 사람에 따라 사용하는 버전이 다를 수 있다는 점에 유의하는 것이 좋습니다.
이번 토픽에서 사용된 라이브러리의 버전은 아래와 같습니다.
numpy: 1.13.3
pandas: 0.23.4
sklearn: 0.20.2
여러분의 PC에서 직접 실습하는 경우에는 PC에 설치된 라이브러리 버전이 더 낮거나 높다면 실습 결과가 달라질 수 있다는 점 참고해 주세요. (코드잇 실행기를 사용하면 영상과 동일한 실습이 가능합니다!)
03. 머신 러닝이 핫해진 이유
1. 사용할 수 있는 데이터가 많아졌다!
- 경험(E) 이란 건 결국 데이터를 통해서 하는 것이기 때문
- 데이터가 충분히 없으면 머신 러닝을 할 수 없다
2. 컴퓨터 성능이 좋아졌다!
- 머신 러닝으로 의미 있는 결과물을 내기 위해서는 많은 데이터를 갖고 많은 연산을 해야 한다
- 데이터를 빠르게 연산하기 위해서는 좋은 컴퓨터가 필요하다
3. 머신 러닝의 활용성이 증명되었다!

머신 러닝 => 좋은 제품 + 수익 창출 => 머신 러닝 인재 모여!!
04. 인공 지능? 빅 데이터? 머신 러닝?




05. 학습의 유형
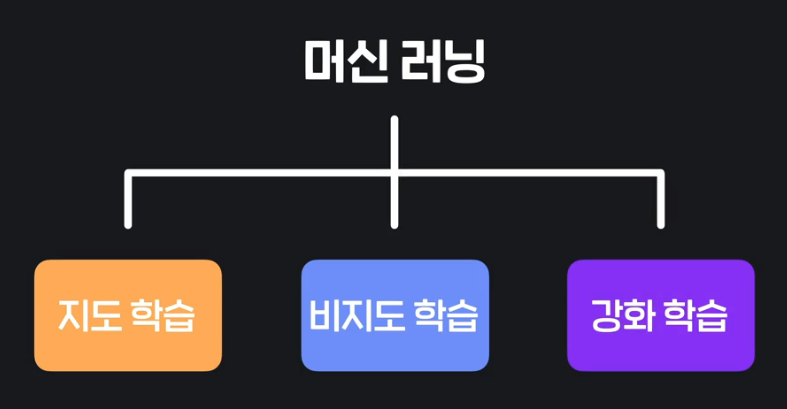
지도 학습 (Supervised Laearning)
: "답"이 있고 이 답을 맞추는 게 학습의 목적
ex) 스팸 메일 분류 프로그램, 아파트 가격 예측 프로그램
=> 지도 학습은 크게 2가지로 나뉨

- 분류 : 스팸 메일 분류 프로그램
- 회귀 : 아파트 가격 예측 프로그램
Q. 지도 학습은 왜 지도 학습일까?
A. 학습 데이터의 답을 정해줘야 한다. 답을 알려주며 지도를 했기 때문에 지도 학습이라고 부른다

비지도 학습 (Unsupervised Learning)
: "답"이 없고 이 답을 맞추는 게 학습의 목적
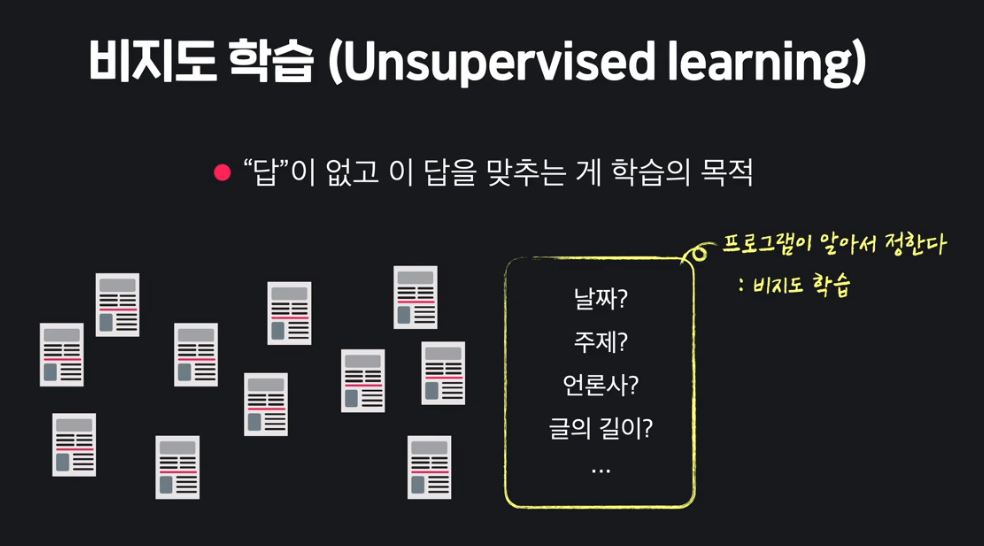
Q. 비지도 학습은 왜 비지도 학습일까?
A. "답"을 가르쳐 주지 않음


강화 학습
: 알파고에 쓰인 핵심 개념 중 하나
06. k-NN 알고리즘
K-최근접 이웃 알고리즘

ex) 타이타닉 탑승자 생존 여부 예측 프로그램
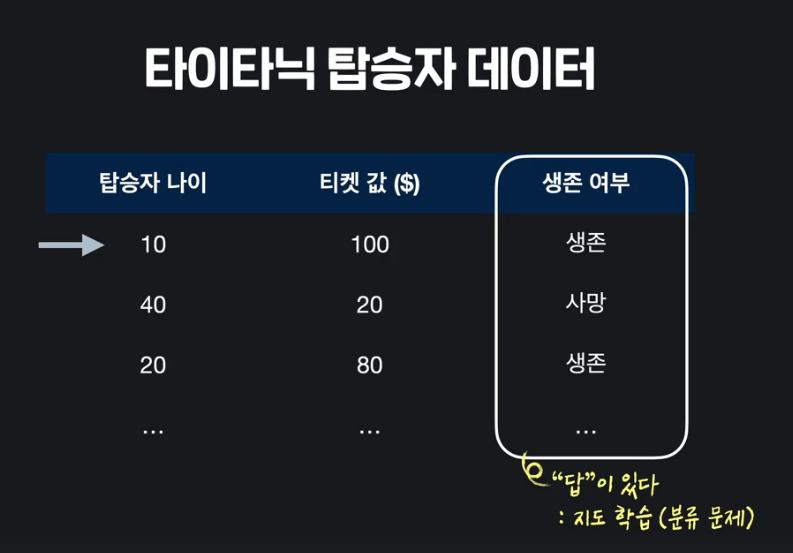
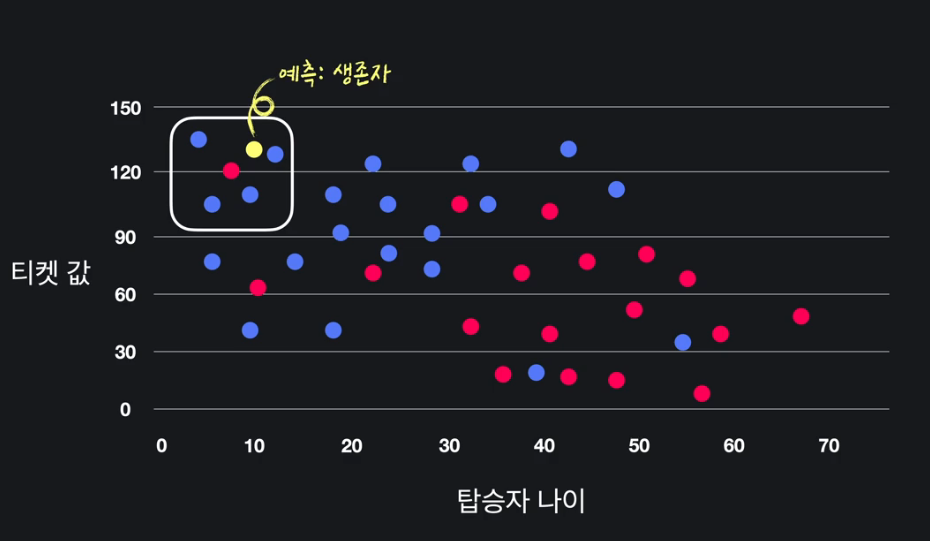
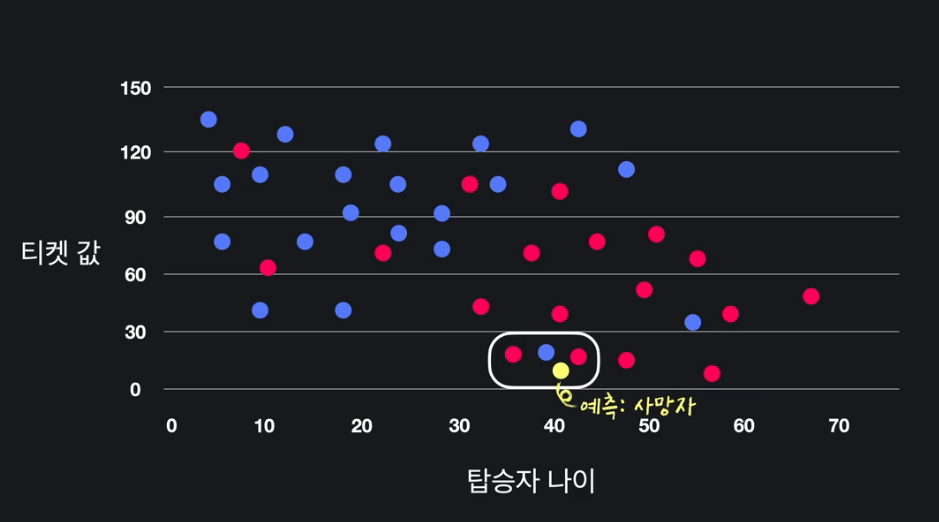
Q, KNN 알고리즘 = 머신러닝?
A. 많은 경험을 하면 성능 향상되서 머신 러닝 이라고 부를 수 있다
07. 머신 러닝의 수학

머신 러닝
: 결국 많은 데이터를 갖고 다양한 계산을 해서 어떤 예측을 하는 것
선형대수학
: 주로 그 데이터들을 행렬로 묶어서 사용하는데 사용

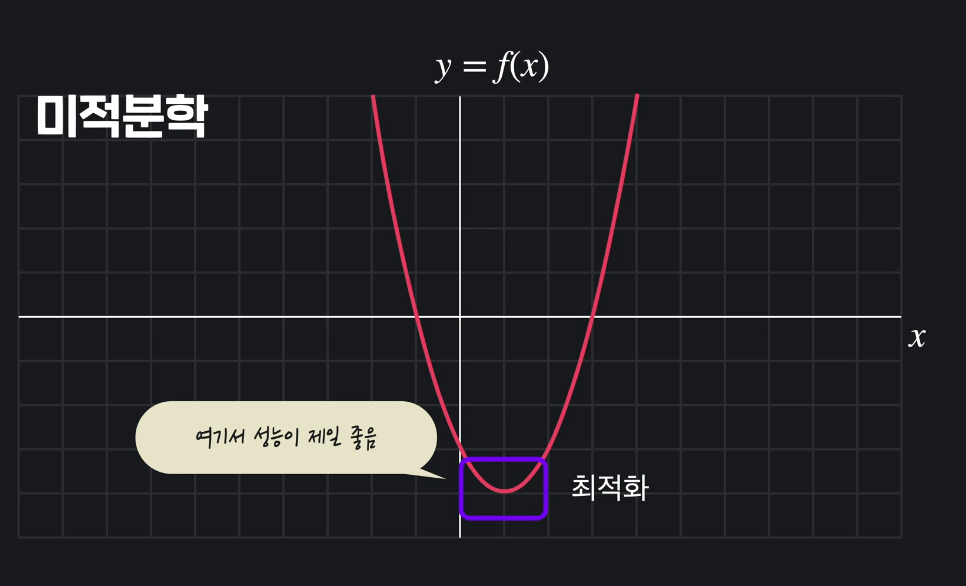
미적분학
: 최적화를 하는 과정
통계
: 많은 데이터를 갖고 그 데이터의 특징을 파악하기 위해 사용

확률
: 가능성을 공부하는 학문

'머신러닝 > 대학 수업' 카테고리의 다른 글
| [코드잇] 딥 러닝 기본기 (1) | 2024.08.28 |
|---|