
3. 연결리스트
1. 연결리스트의 소개
- 연결 리스트란?
연결리스트는 동적으로 크기가 변할 수 있고, 삭제나 삽입시에 데이터 이동이 필요없는 연결된 표현(linked representation)(데이터와 링크로 구성, 링크가 데이터들을 연결하는 역할을 함)임.
연결 리스트(linked list): 물리적으로 흩어져 있는 자료들을 서류 연결하여 하나로 묶는 방법
장점: 삽입, 삭제시 데이터 이동이 필요없음, 데이터 저장 공간을 동적으로 생성할 수 있음
단점: 연산의 구현이나 사용방법이 배열에 비해 복잡하여 오류 발생 가능성이 높음, 링크 필드를 위한 추가 공간 필요
- 연결리스트의 구조
노드(node) = 데이터 필드(data field, 저장하고 싶은 데이터) + 링크 필드(link field, 다른 노드를 가리키는 포인터)
-연결 리스트는 노드의 집합
-노드는 어떤 위치에나 있을 수 있으며, 다른 노드로 가기 위해서는 현재 노드가 가지고 있는 포인터를 이용하면 됨
-연결 리스트에서 첫 번째 노드를 알아야 전체 노드를 접근할 수 있음. 따라서, 첫 번째 노드를 가리키고 있는 변수가 필요한데, 이를 헤드 포인터(head pointer)라고 함
-연결 리스트에서 마지막 노드의 일크는 NULL로 설정, 이는 더 이상 연결된 노드가 없다는 것을 의미함
- 단순 연결 리스트(singly linked list): 하나의 방향으로만 연결되어 있음. 맨 마지막 노드의 링크 필드는 NULL 값을 가짐
- 원형 연결 리스트(circular linked list): 단순 연결 리스트와 같으나 맨 마지막 노드 링크 필드가 첫 번째 노드를 가리킴
- 이중 연결 리스트(doubly linked list): 각 노드마다 링크 필드가 2개씩 존재하며 앞, 뒤 노드를 가리키고 있음.
Quiz
- 단순 연결 리스트에서 첫 번쨰 노드를 가리키고 있는 포인터를 헤드 포인터라고 한다.
- 노드는 데이터 필드와 링크 필드로 이루어져 있다.
- 배열에 비하여 연결 리스트는 어떤 장점을 가지는가? -> 삽입, 삭제시 데이터 이동이 필요없고, 데이터 저장 공간을 동적으로 생성할 수 있음
2. 단순 연결 리스트
- 단순 연결 리스트 소개
단순 연결 리스트는 노드들이 하나의 링크 필드를 가지며 이 링크 필드를 이용하여 모든 노드들이 연결되어 있음. 마지막 노드의 링크 필드 값은 NULL이 됨
<알고리즘 4.3.2.1> 단순 연결 리스트에서의 삽입 알고리즘
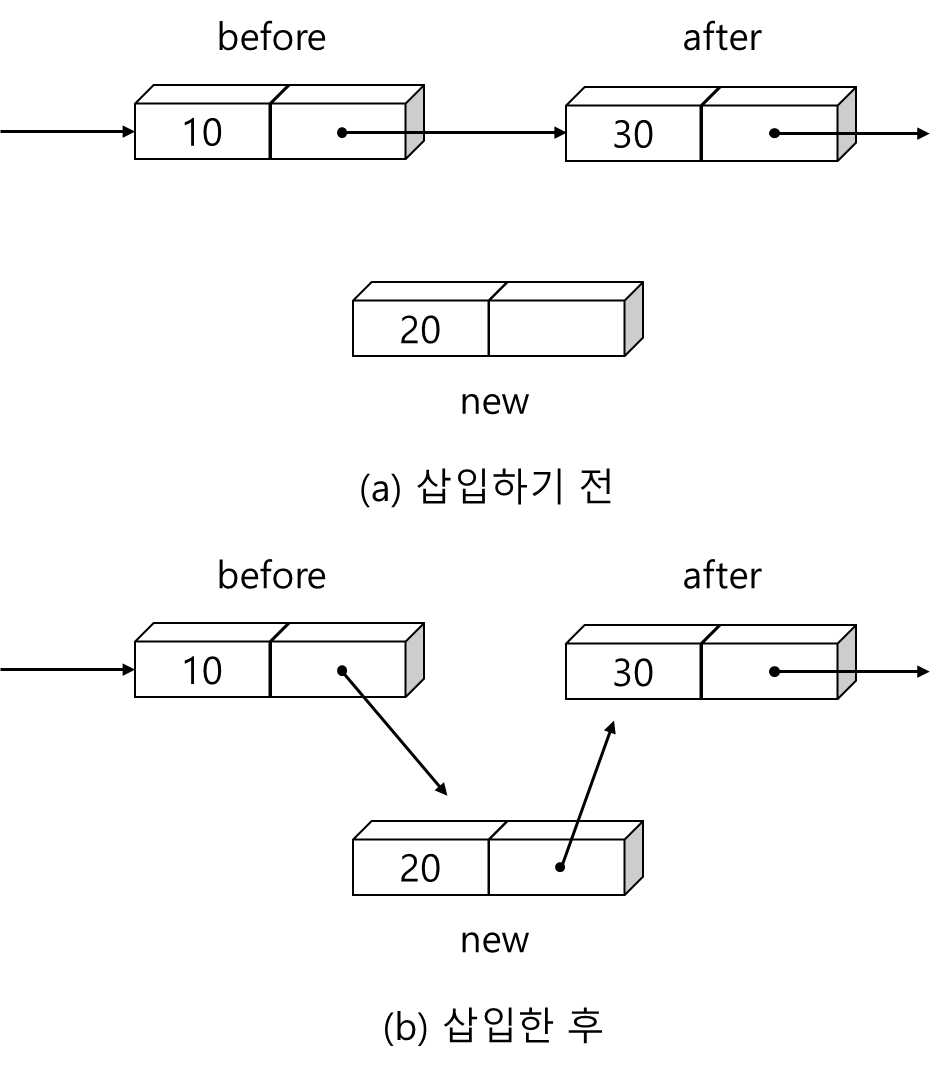
insert_node(L,before,new)
if L = NULL
then L <- new
else new.link <- before.link
before.link <- new
1. 만약 연결 리스트 L이 공백 상태라면
2. 새로운 노드를 첫 번째 노드로 함
3. 그렇지 않으면 new 노드의 링크가 after를 가리키게 하고(after 노드의 주소가 before 노드의 링크에 저장되어 있음)
4. befor의 링크가 new를 가리키게 함.<알고리즘 4.3.2.2> 단순 연결 리스트에서의 삭제 알고리즘
remove_node(L,before, removed)
if L != NULL
then befor.link <- removed.link
destory(removed)
1. 만약 연결 리스트 L이 공백 상태가 아니라면
2. before 노드의 링크가 after를 가리키게 하고(after 노드의 주소가 removed 노드의 링크에 저장되어 있음)
3. removed 노드를 삭제함- 단순 연결 리스트의 구현
// 단순 연결 리스트 구조체 생성
typedef int element;
typedef struct ListNode{
element data;
struct ListNode* link;
}ListNode;
// 연결 리스트에서는 필요 시에 노드를 동적으로 생성
ListNode *p1;
p1 = (ListNode *)malloc(struct(ListNode));
p1->data = 10;
p1->link = NULL;
// 두 개의 노드를 연결
ListNode *p2;
p2 = (ListNode *)malloc(struct(ListNode));
p2->data = 20;
p2->link = NULL;
p1->link = p2;
// 메모리 해제
free(p1);
free(p2);- 삽입 연산
<프로그램 4.3.2.1> 단순 연결 리스트 삽입 함수
- head가 NULL인 경우: head가 NULL이라면 현재 삽입하려는 노드가 첫번째 노드가 됨. 따라서, head의 값만 변경하면 됨

- p가 NULL인 경우: 선행 노드 p가 NULL 값일 때는 리스트의 맨 앞에 삽입. 먼저, new_node의 link가 head와 같은 값을 갖도록하고 다음에 head가 new_node를 가리키도록 함
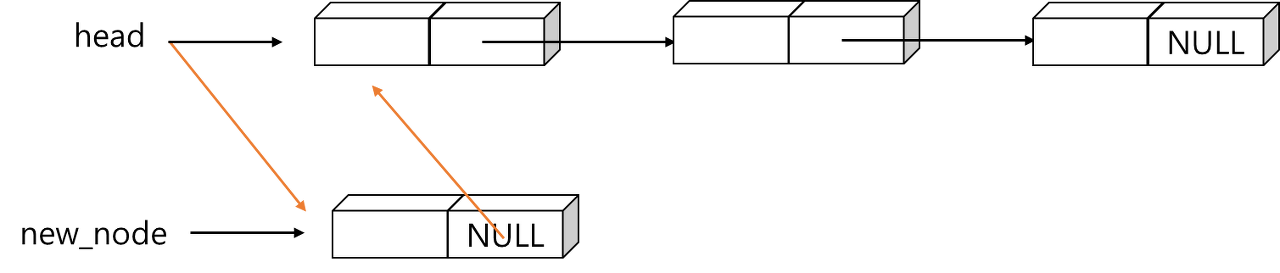
- head와 p가 NULL이 아닌 경우: 가장 일반적인 경우, new_node의 link에 p->link 값을 복사한 다음, p->link가 new_node를 가리키도록 함

// phead: 리스트의 헤드 포인터 head에 대한 포인터
// p: 삽입될 위치의 선행 노드를 가리키는 포인터, 이 노드 다음에 삽입 됨
// new_node: 새로운 노드를 가리키는 포인터, 삽입될 노드
void insert_node(ListNode** phead, ListNode* p, ListNode* new_node)
{
if (*phead == NULL) { // 공백 리스트인 경우
new_node->link = NULL;
*phead = new_node;
} else if (p == NULL) { // p가 NULL이면 첫 번째 노드로 삽입
new_node->link = *phead;
*phead = new_node;
} else { // p 다음에 삽입
new_node->link = p->link;
p->link = new_node;
}
}- 삭제 연산
(1) p가 NULL인 경우: 연결 리스트의 첫 번째 노드를 삭제, 헤드 포인터를 변경하고 removed 노드가 차지하고 있는 공간을 시스템에 반환
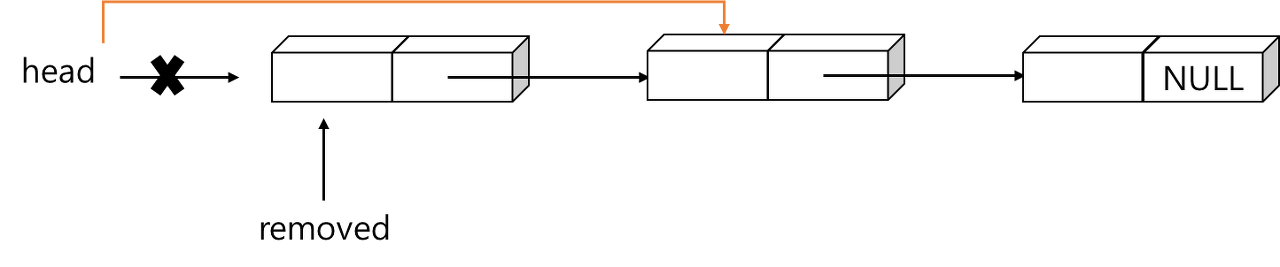
(2) p가 NULL이 아닌 경우: 먼저 removed 앞의 노드인 p의 링크가 removed 다음 노드를 가리키도록 변경, 추가 작업으로 removed 노드가 차지하고 있는 공간을 시스템에 반환

<프로그램 4.3.2.2> 단순 연결 리스트 삭제 함수
// phead: 헤드 포인터 head의 포인터
// p: 삭제될 노드의 선행 노드를 가리키는 포인터
// removed: 삭제될 노드를 가리키는 포인터
void remove_node(ListNode **phead, ListNode *p, ListNode *removed){
if(p == NULL){
*phead = (*phead)->link;
}else{
p->link = removed->link;
}
free(removed);
}- 방문 연산
<프로그램 4.3.2.3> 반복적인 리스트 방문 알고리즘
void display(ListNode *head){ // 매개변수: 첫 번째 노드를 가리키는 포인터
ListNode *p = head;
while(p!=NULL){ // 노드의 링크 값이 NULL이 아니면
printf("%d->",p->data);
p = p->link; // 계속 링크를 따라가면서 노드를 방문
}
printf("\n");
}<프로그램 4.3.2.4> 순환적인 리스트 탐색 알고리즘
void display_recur(ListNode *head){
ListNode *p = head;
if(p!=NULL){
printf("%d->",p->data);
display_recur(p->link);
}
}- 탐색 연산
- 포인터 p가 첫 번째 노드를 가리키도록 함
- 순서대로 링크를 따라가면서 노드의 데이터와 비교
- 링크 값이 NULL이면 연결 리스트 끝에 도달한 것이므로 탐색 중단
- 반환 값은 탐색 값을 가지고 있는 노드를 가리키는 포인터
<프로그램 4.3.2.5> 노드 값 탐색 알고리즘
ListNode *search(ListNode *head, element item){
ListNode *p = head;
while(p!=NULL){
if(p->data == item) return p; // 탐색 성공
p = p->link;
}
return p; // 탐색 실패 NULL 반환
}- 두 개의 리스트 L1과 L2를 하나로 만드는 연산
첫 번째 리스트의 맨 끝으로 간 다음, 마지막 노드의 링크가 두 번째 리스트의 맨 처음 노드를 가리키도록 변경하면 됨, head1, head2가 NULL인 경우를 반드시 처리해야 함
<프로그램 4.3.2.6> 연결 리스트 연결 알고리즘
ListNode *concat(ListNode *head1, ListNode *head2){
ListNode*p;
if(head1 == NULL) return head2;
else if(head2 == NULL) return head1;
else{
p = head1;
while(p->link != NULL){
p = p->link;
}
p->link = head2;
return head1;
}
}- 리스트를 역순으로 만드는 연산
3개의 포인터를 이용해서 연결 리스트를 순회하면서 링크의 방향을 역순으로 바꾸면 됨, 링크의 방향을 역순으로 바꾸기 전에 미리 뒤의 노드를 알아놓아야 함
<프로그램 4.3.2.7> 연결 리스트 역순 알고리즘
ListNode *reverse(ListNode *head){
// 순회 포인터로 p,q,r을 사용
ListNode *p,*q,*r;
p = head; // p는 아직 처리되지 않은 노드
q = NULL; // q는 역순으로 만들 노드
while(p!=NULL){
r = q; // r은 역순으로 된 노드 r은 q, q는 p를 차례를 따라간다.
q = p;
p = p->link;
q->link = r; // q 링크의 방향을 바꾼다.
}
return q; // q는 역순으로 된 리스트의 헤드 포인터
}- 전체 테스트 프로그램
<프로그램 4.3.2.8> 전체 테스트 프로그램
#include <stdio.h>
#include <stdlib.h>
// (추가)오류 처리 함수
void error(const char*message){
fprintf(stderr, "%s\n", message);
exit(1);
}
// (추가)노드를 동적으로 생성하는 프로그램
ListNode * create_node(element data, ListNode *link){
ListNode *new_node;
new_node = (ListNode*)malloc(sizeof(ListNode));
if(new_node == NULL) error("memory allocate error");
new_node->data = data;
new_node->link = link;
return new_node;
}
// 테스트 프로그램
int main(){
ListNode *list1 = NULL, *list2 = NULL;
ListNode* p;
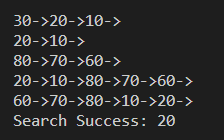
//list1 = 30->20->10
insert_node(&list1, NULL, create_node(10, NULL));
insert_node(&list1, NULL, create_node(20, NULL));
insert_node(&list1, NULL, create_node(30, NULL));
display(list1);
// list1 = 20->10
remove_node(&list1, NULL, list1);
display(list1);
// list2 = 80->70->60
insert_node(&list2, NULL, create_node(60, NULL));
insert_node(&list2, NULL, create_node(70, NULL));
insert_node(&list2, NULL, create_node(80, NULL));
display(list2);
// list1 = list1 + list2
list1 = concat(list1, list2);
display(list1);
// list1을 역순으로
list1 = reverse(list1);
display(list1);
// list1에서 20 탐색
p = search(list1, 20);
printf("Search Success: %d\n", p->data);
return 0;
}
Quiz
- 단순 연결 리스트에서 하나의 노드를 삭제하려면 어떤 노드를 가리키는 포인터 변수가 필요한가? -> 첫 번째 노드를 가리키는 포인터의 포인터 변수, 삭제하려고 하는 노드의 선행 노드의 포인터 변수, 삭제하려는 노드의 포인터 변수
- 단순 연결 리스트에 존재하는 노드의 수를 계산하는 get_length()를 작성하여라
int get_length(ListNode *head){
int cnt = 0;
ListNode* p = head;
while(p!=NULL){
p = p->link;
cnt++;
}
return cnt;
}3. 원형 연결 리스트
- 원형 연결 리스트 소개
원형 연결 리스트: 리스트의 마지막 노드의 링크가 첫 번째 노드를 가리키는 리스트
-> 마지막 노드는 헤드 포인터인 head가 가리키고 있고, 첫 번째 노드는 head->link가 가리키고 있음
장점: 한 노드에서 다른 모든 노드로의 접근이 가능하기 때문에 삭제나 삽입이 단순 연결 리스트보다는 용이해짐
삽입 함수
- 새로운 노드의 링크인 node->link가 첫 번째 노드를 가리키게 함
- 마지막 노드의 링크가 node를 가리키면 됨
<프로그램 4.3.3.1> 원형 연결 리스트 처음에 삽입하는 함수
// phead: 리스트의 헤드 포인터의 포인터
// node: 삽입될 노드
void insert_first(ListNode **phead, ListNode *node){
if(*phead == NULL){
*phead = node;
node->link = node;
}else{
node->link = (*phead)->link;
(*phead)->link = node;
}
}<프로그램 4.3.3.2> 원형 연결 리스트 삽입 알고리즘
// phead: 리스트의 헤드 포인터의 포인터
// node: 삽입될 노드
void insert_last(ListNode **phead, ListNode *node){
if(*phead == NULL){
*phead = node;
node->link = node;
}else{
node->link = (*phead)->link;
(*phead)->link = node;
*phead = node; // head의 위치만 새로운 노드로 바꿔주면 새로운 노드가 마지막 노드가 됨
}
}테스트 프로그램
<프로그램 4.3.3.3> 원형 연결 리스트 테스트 프로그램
#include <stdio.h>
#include <stdlib.h>
typedef int element;
typedef struct ListNode{
element data;
struct ListNode* link;
}ListNode;
void error(const char* message){
fprintf(stderr, "%s\n", message);
exit(1);
}
// 노드를 동적으로 생성하는 프로그램
ListNode* create_node(element data, ListNode* link)
{
ListNode* new_node;
new_node = (ListNode*)malloc(sizeof(ListNode));
if (new_node == NULL)
error("memory allocate error");
new_node->data = data;
new_node->link = link;
return new_node;
}
// 리스트의 항목 출력
void display(ListNode* head)
{
ListNode* p;
if (head == NULL)
return;
p = head;
do {
p = p->link;
printf("%d->", p->data);
} while (p != head); // 마지막 노드의 링크가 9이 아니기 때문에 리스트의 끝에 도달했는지를 검사하려면 헤드 포인터와 비교해야 함
printf("\n");
}
int main(){
ListNode* list1 = NULL;
// list1 = 20->10->30
insert_first(&list1, create_node(10, NULL));
insert_first(&list1, create_node(20, NULL));
insert_last(&list1, create_node(30, NULL));
display(list1);
return 0;
}
Quiz
- 단순 연결 리스트에 비하여 원형 연결 리스트의 장점? -> 한 노드에서 다른 모든 노드로의 접근이 가능하다는 것. 하나의 노드에서 링크를 계속 따라가면 결국 모든 노드를 거쳐서 자기 자신으로 되돌아올 수 있으므로 어떤 노도로드 갈 수 있음. 따라서, 노드의 삽입과 삭제가 단순 연결 리스트보다는 용이해짐
- 원형 연결 리스트에 존재하는 노드의 수를 계산하는 함수 get_length()를 작성하라.
int get_length(ListNode* head)
{
int cnt = 0;
ListNode* p = head;
do {
p = p->link;
cnt++;
} while (p != head);
return cnt;
}4. 이중 연결 리스트
이중 연결 리스트: 하나의 노드가 선행 노드와 후속 노드에 대한 두 개의 링크를 가지는 리스트
장점: 양방향으로 검색이 가능
단점: 공간을 많이 차지하고, 코드가 복잡해짐
-헤드 노드(head node)라는 특별한 노드를 축하는 경우가 많음 (헤드 포인터와 구별해야 함)
-헤드 포인터: 리스트의 첫 번째 노드를 가리키는 포인터
-헤드 노드: 데이터를 가지고 있지 않은 특별한 노드
이중 연결 리스트 노드 = 왼쪽 링크 필드 + 데이터 필드 + 오른쪽 링크 필드
-> 이중 연결 리스트에서 임의의 노드를 가리키는 포인터를 p라 하면, p == p->llink->rlink == p->rlink->llink 관계가 항상 성립됨
// 이중 연결 리스트 구조체 생성
typedef int element;
typedef struct DlistNode{
element data;
struct DlistNode *llink;
struct DlistNode *rlink;
}DlistNode;- 삽입 연산
<프로그램 4.3.4.1> 이중 연결 리스트에서의 삽입 함수
// 노드 new_node를 노드 before의 오른쪽에 삽입
void dinsert_node(DlistNode *before, DlistNode *new_node){
new_node->llink = before;
new_node->rlink = before->rlink;
before->rlink->llink = new_node;
before->rlink = new_node;
}- 삭제 연산
<프로그램 4.3.4.2> 이중 연결 리스트에서의 삭제 함수
// 노드 removed를 삭제
void dremove_node(DlistNode *phead_node, DlistNode *removed){
if(removed == phead_node) return;
removed->llink->rlink = removed->rlink;
removed->rlink->llink = removed->llink;
free(removed);
}- 완전한 프로그램
<프로그램 4.3.4.3> 이중 연결 리스트에서의 삭제 함수
#include <stdio.h>
#include <stdlib.h>
#include <memory.h>
#include <string.h>
// 이중 연결 리스트 초기화
void init(DlistNode *phead){
phead->llink = phead;
phead->rlink = phead;
}
// 이중 연결 리스트의 노드들 출력
void display(DlistNode *phead){
DlistNode* p;
for (p = phead->rlink; p != phead;p=p->rlink){
printf("<--- | %x | %d | %x | --->\n", p->llink, p->data, p->rlink);
}
printf("\n");
}
int main(){
DlistNode head_node;
DlistNode* p[10];
init(&head_node);
for (int i = 0; i < 5;i++){
p[i] = (DlistNode*)malloc(sizeof(DlistNode));
p[i]->data = i;
// 헤드 노드의 오른쪽에 삽입
dinsert_node(&head_node, p[i]);
}
dremove_node(&head_node, p[4]);
display(&head_node);
return 0;
}
Quiz
- 이중 연결 리스트에서 헤드 노드를 사용하는 이유? -> 헤드 노드가 존재하게 되면 삽입, 삭제 알고리즘이 간편해지기 때문
- 헤드 노드만 있는 공백 상태의 이중 연결 리스트에 노드를 삽입하기 위하여 dinsert_node()를 호출하였다면 포인터들은 어떻게 변경되는가? 그림으로 설명

5. 연결 리스트 응용: 다항식
- 단순 연결 리스트에서 다항식의 각 항이 노드로 표현됨
typedef struct ListNode{
int coef; // 계수
int expon; // 지수
struct ListNode *link; // 다음 항을 가리키는 링크
}ListNode;ex) 2개의 다항식을 더하는 뎃셈 연산 c(x) = a(x) + b(x)를 구현
1. p.expon == q.expon: 두 계수를 더해서 0이 아니면 새로운 항을 만들어 다항식 c에 추가, 그리고 p와 q는 모두 다음 항으로 이동
2. p.expon < q.expon: q가 가리키는 항을 새로운 항으로 복사하여 다항식 c에 추가, 그리고 q만 다음 항으로 이동
3. p.expon > q.expon: p가 가리키는 항을 새로운 항으로 복사하여 다항식 c에 추가, 그리고 p만 다음 항으로 이동
효율적인 계산을 위해서 연결 리스트의 첫 번째 노드와 마지막 노드를 가리키는 포인터를 동시에 사용 -> 이를 헤더 노드를 통해 관리(따라서, 헤드 노드는 이중 연결 리스트)
<프로그램 4.3.5.1> 이중 연결 리스트의 다항식 프로그램
#include <stdio.h>
#include <stdlib.h>
// 연결 리스트의 노드의 구조
typedef struct ListNode {
int coef;
int expon;
struct ListNode* link;
} ListNode;
// 연결 리스트 헤더
typedef struct ListHeader {
int length;
ListNode* head;
ListNode* tail;
} ListHeader;
// 초기화 함수
void init(ListHeader* plist)
{
plist->length = 0;
plist->head = plist->tail = NULL;
}
// 오류 처리 함수
void error(const char* message){
fprintf(stderr, "%s\n", message);
exit(1);
}
// plist: 연결 리스트의 헤더를 가리키는 포인터
// coef: 계수
// expon: 지수
void insert_node_last(ListHeader *plist, int coef, int expon){
ListNode* tmp = (ListNode*)malloc(sizeof(ListNode));
if(tmp == NULL)
error("memory allocate error");
tmp->coef = coef;
tmp->expon = expon;
tmp->link = NULL;
if(plist->tail == NULL){
plist->head = plist->tail = tmp;
}else{
plist->tail->link = tmp;
plist->tail = tmp;
}
plist->length++;
}
//list3 = list1 + list2
void poly_add(ListHeader *plist1,ListHeader *plist2, ListHeader*plist3){
ListNode* p = plist1->head;
ListNode* q = plist2->head;
int sum;
while(p!=NULL && q!=NULL){
if(p->expon == q->expon){ // p의 차수 == q의 차수
sum = p->coef + q->coef;
if(sum !=0 ){
insert_node_last(plist3, sum, p->expon);
}
p = p->link;
q = q->link;
}else if(p->expon < q->expon){ // p의 차수 < q의 차수
insert_node_last(plist3, q->coef, q->expon);
q = q->link;
} else { // p의 차수 > q의 차수
insert_node_last(plist3, p->coef, p->expon);
p = p->link;
}
}
// p와 q중의 하나가 먼저 끝나게 되면 남아 있는 항들을 모두 결과 다항식으로 복사
if(p!=NULL){
for (; p != NULL; p = p->link) {
insert_node_last(plist3, p->coef, p->expon);
}
}
if(q!=NULL){
for (; q != NULL;q=q->link){
insert_node_last(plist3, q->coef, q->expon);
}
}
}
// 다항식 출력 함수
void poly_display(ListHeader *plist){
ListNode* tmp = plist->head;
for (; tmp != NULL; tmp=tmp->link){
printf("coef: %d, expon: %d\n", tmp->coef, tmp->expon);
}
printf("\n");
}
// 이중 연결 리스트의 응용 프로그램
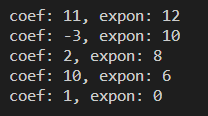
int main(){
ListHeader list1, list2, list3;
// 연결 리스트 초기화
init(&list1);
init(&list2);
init(&list3);
// 다항식1을 생성(list1)
insert_node_last(&list1, 3, 12);
insert_node_last(&list1, 2, 8);
insert_node_last(&list1, 1, 0);
// 다항식2를 생성(list2)
insert_node_last(&list2, 8, 12);
insert_node_last(&list2, -3, 10);
insert_node_last(&list2, 10, 6);
// 다항식3 = 다항식1 + 다항식2
poly_add(&list1, &list2, &list3);
poly_display(&list3);
return 0;
}
'자료구조와 알고리즘 ft. 수업 > 알고리즘 정리' 카테고리의 다른 글
| 3. 스택의 응용 (0) | 2023.03.07 |
|---|---|
| 2. 스택의 구현 (0) | 2023.03.07 |
| 1. 스택 ADT (0) | 2023.03.07 |
| 3. 연결 리스트로 구현된 리스트 (0) | 2023.03.07 |
| 1. 리스트 (0) | 2023.03.07 |