
1. Python Basics

def reverse_string(s: str) -> str:
reversed_str = ""
for char in s:
reversed_str = char + reversed_str
return reversed_str
def reverse_string(s: str) -> str:
return s[::-1]def count_words(s: str) -> int:
words = s.split()
return len(words)

def find_intersection(list1, list2):
return [item for item in list1 if item in list2]
def find_intersection(list1, list2):
set1 = set(list1)
set2 = set(list2)
intersection = set1.intersection(set2)
return list(intersection)def get_word_lengths(words):
return [len(word) for word in words]
def char_count(input_string):
frequency_dict = {}
for char in input_string:
if char in frequency_dict:
frequency_dict[char] += 1
else:
frequency_dict[char] = 1
return frequency_dict2. Numpy Dataframe SQL

import random
import time
import numpy as np
# 1. 리스트로 구현
start_time_list = time.time()
random_list = [random.randint(0, 1000) for _ in range(1000000)]
# 500보다 큰 수는 1, 500 이하의 수는 0으로 변환한 새로운 리스트 생성
binary_list = [1 if x > 500 else 0 for x in random_list]
end_time_list = time.time()
list_time = end_time_list - start_time_list
print(f"리스트 처리 시간: {list_time} 초")
# 2. numpy 배열로 구현
start_time_array = time.time()
# 백만개의 0부터 1000 사이의 정수 배열 생성
random_array = np.random.randint(0, 1001, 1000000)
# 500보다 큰 수는 1, 500 이하의 수는 0으로 변환한 새로운 배열 생성
binary_array = np.where(random_array > 500, 1, 0)
end_time_array = time.time()
array_time = end_time_array - start_time_array
print(f"배열 처리 시간: {array_time} 초")
# 결과 출력
if list_time < array_time:
print(f"리스트가 배열보다 {array_time - list_time} 초 더 빨랐습니다.")
else:
print(f"배열이 리스트보다 {list_time - array_time} 초 더 빨랐습니다.")
# 몇 배 더 빨랐는지 계산
if array_time < list_time:
speedup_factor = list_time / array_time
print(f"배열이 리스트보다 {speedup_factor:.2f}배 더 빨랐습니다.")
else:
speedup_factor = array_time / list_time
print(f"리스트가 배열보다 {speedup_factor:.2f}배 더 빨랐습니다.")
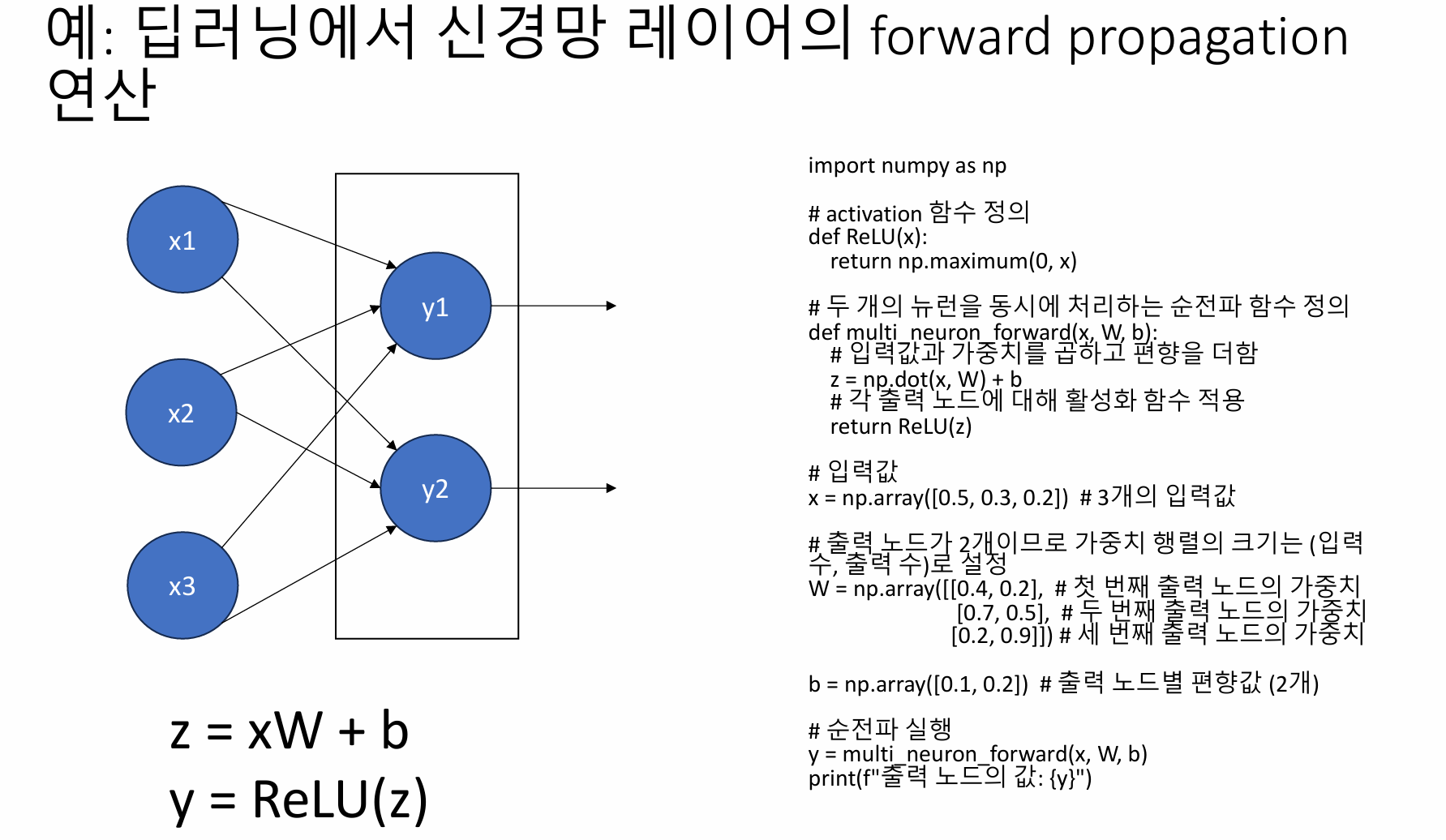
다음은 신경망의 **forward propagation**(순전파) 과정을 Numpy를 사용하여 구현한 코드입니다. 이 코드는 입력값, 가중치, 편향을 이용하여 두 출력값을 계산하는 예시입니다.
import numpy as np
# ReLU 활성화 함수 정의
def ReLU(x):
return np.maximum(0, x)
# 두 개의 뉴런을 동시에 처리하는 순전파 함수 정의
def multi_neuron_forward(x, W, b):
# 입력값과 가중치를 곱하고 편향을 더함
z = np.dot(x, W) + b
# 각 출력 노드에 대해 활성화 함수(ReLU) 적용
return ReLU(z)
# 입력값 (x1, x2, x3)
x = np.array([0.5, 0.3, 0.2]) # 3개의 입력값
# 가중치 행렬 (3개의 입력값에서 2개의 출력값으로)
W = np.array([[0.4, 0.2], # 첫 번째 출력 노드의 가중치
[0.7, 0.5], # 두 번째 출력 노드의 가중치
[0.2, 0.9]]) # 세 번째 출력 노드의 가중치
# 출력 노드별 편향값 (2개의 출력 노드)
b = np.array([0.1, 0.2])
# 순전파 실행
y = multi_neuron_forward(x, W, b)
# 출력값 출력
print(f"출력 노드의 값: {y}")
### 코드 설명:
1. **ReLU 함수**: `ReLU(x)`는 입력값이 0보다 크면 그대로, 작으면 0으로 만드는 활성화 함수입니다.
2. **순전파 함수**: `multi_neuron_forward` 함수는 입력값 `x`, 가중치 `W`, 편향 `b`를 사용해 `z = xW + b` 공식을 적용하고, 그 결과에 ReLU 활성화 함수를 적용한 후 출력합니다.
3. **입력값**: `x`는 3개의 입력값으로 이루어진 배열입니다. (`[0.5, 0.3, 0.2]`)
4. **가중치**: `W`는 3개의 입력값에서 2개의 출력값을 계산하기 위한 가중치 행렬입니다.
5. **편향**: `b`는 2개의 출력 노드 각각에 더해지는 편향값입니다.
6. **출력**: `y`는 순전파 후 두 출력값을 나타냅니다.
이 코드가 실행되면 두 출력 노드에서 계산된 값이 출력됩니다. Forward propagation의 간단한 예시로, 신경망이 어떻게 입력값을 받아 출력값을 계산하는지 보여줍니다.
3. Understanding on Data
4. Data Summary and Visualization
요약 통계의 주요 용어와 그 의미는 다음과 같습니다:
1. **평균 (Mean)**: 데이터의 전체 합을 데이터 개수로 나눈 값으로, 데이터의 중심 위치를 나타냅니다. 하지만 이상치에 민감합니다.
2. **중앙값 (Median)**: 데이터 값을 크기 순으로 나열했을 때 중간에 위치한 값으로, 평균보다 이상치에 덜 민감합니다.
3. **최빈값 (Mode)**: 데이터 집합에서 가장 자주 나타나는 값으로, 주로 범주형 데이터에 사용됩니다.
4. **빈도 (Frequency)**: 특정 값이나 범주가 데이터 내에서 얼마나 자주 나타나는지를 백분율로 표현한 값입니다.
5. **분산 (Variance)**: 데이터 각 값이 평균과 얼마나 떨어져 있는지의 정도를 나타내는 값입니다. 평균에서의 거리의 제곱을 합한 뒤 데이터 개수로 나누어 계산합니다.
6. **표준 편차 (Standard Deviation)**: 분산의 제곱근으로, 데이터의 퍼짐 정도를 나타냅니다. 분산과 마찬가지로 데이터가 평균에서 얼마나 떨어져 있는지를 보여줍니다.
7. **백분위수 (Percentile)**: 데이터의 특정 위치를 백분율로 나타내는 값입니다. 예를 들어, 25번째 백분위수는 데이터의 하위 25%에 해당하는 값이며, 이를 통해 데이터의 분포를 더 잘 이해할 수 있습니다.
8. **사분위수 (Quartile)**: 데이터 분포를 네 부분으로 나눈 값입니다. Q1은 하위 25%, Q3는 상위 75%로, 두 값의 차이를 IQR(사분위수 범위)라고 하며, 이상치를 파악하는 데 유용합니다.
1. **요약 통계**: 평균, 중앙값, 최빈값, 빈도, 분산, 표준 편차 등으로 데이터의 특성을 요약합니다.
2. **데이터 분포**: 대칭 데이터와 왜도 있는 데이터를 구분합니다.
3. **백분위수**: 연속형 데이터에서 유용하며, 데이터 분포의 25%, 75% 지점을 나타냅니다.
4. **박스플롯**: 최소값, Q1, 중앙값, Q3, 최대값 등 다섯 가지 숫자로 데이터 분포를 시각화하고, 이상치를 강조합니다.
5. **히스토그램**: 카테고리별 빈도 분포를 시각화합니다.
6. **산점도**: 두 변수 간의 관계를 보여주며, 양의 상관관계나 음의 상관관계를 나타냅니다.
7. **Python 활용**: Numpy와 Matplotlib 등을 사용하여 백분위수, 박스플롯, 히스토그램, 산점도 등을 시각화합니다.
5. Data Summary 실습
https://colab.research.google.com/drive/1VnJ4eoNoqonhumMBw8-7rk6_8B_x-xst#scrollTo=uz7HKRRsbBrj
Google Colab Notebook
Run, share, and edit Python notebooks
colab.research.google.com
6. Distance and Similarity
7. embedding
8. Machine Learning and Classification
9. classification 실습
'기타 등등 > 학교 강의 관련 글들' 카테고리의 다른 글
| 인공지능 응용 기말 정리 (0) | 2024.10.19 |
|---|---|
| 기계학습 중간고사 정리 (0) | 2024.10.17 |
| 디지털 논리 회로 중간 정리 (0) | 2024.10.11 |
| 운영체제 공부법 (0) | 2024.03.11 |
| 컴퓨터 그래픽스 (0) | 2024.03.08 |